
Descubra el conjunto de datos FineWeb: optimización de la IA con datos de alta calidad

En inteligencia artificial, la calidad de los datos es un factor determinante en el rendimiento de los modelos de aprendizaje automático. El conjunto de datos FineWeb, desarrollado por Hugging Facerepresenta un avance significativo en este campo.
Diseñado para enriquecer los modelos lingüísticos, este conjunto de datos se distingue por su meticulosa estructura y su importante volumen de datos web preparados, clasificados y anotados. Al explotar datos diversos y bien organizados, el conjunto de datos FineWeb pretende mejorar la precisión y eficacia de los algoritmos de IA. ¿Se pregunta por qué es importante este conjunto de datos y, sobre todo, cómo se construyó? Se lo contamos en este artículo.
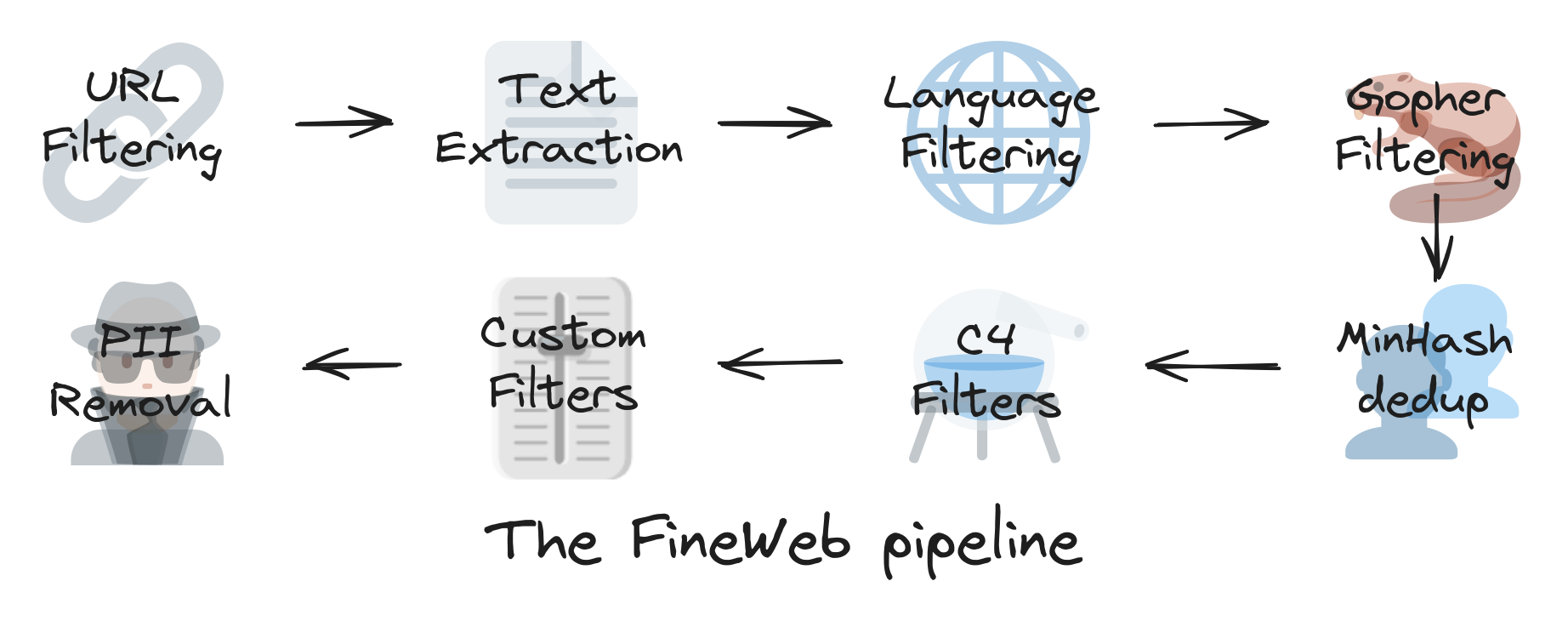
¿Qué es el conjunto de datos FineWeb y por qué es importante?
El FineWeb Dataset es un conjunto de datos desarrollado por Hugging Face, diseñado para mejorar el entrenamiento de los Large Language Models ( LLM).
Este conjunto de datos consiste en datos extraídos de Internet, cuidadosamente filtrados y anotados para garantizar una alta calidad y una mayor relevancia para las aplicaciones de inteligencia artificial. La recopilación de páginas web y la importancia de filtrar las URL para evitar contenidos inapropiados, datos personales o sensibles y garantizar una desduplicación eficaz a nivel de URL son aspectos importantes para mantener la calidad de los datos.
Su importancia radica en su capacidad para proporcionar datos diversos y precisos, esenciales para el desarrollo de modelos de IA robustos y de alto rendimiento. Al optimizar la calidad de los datos utilizados para el entrenamiento, el conjunto de datos FineWeb contribuye a mejorar la precisión, coherencia y eficacia de los modelos lingüísticos. Esto lo convierte en un valioso recurso para los desarrolladores y entusiastas de la IA que trabajan en aplicaciones que requieren una comprensión precisa del lenguaje natural.
¿En qué se diferencia el conjunto de datos FineWeb de otros conjuntos de datos de IA?
El sitio conjunto de datos FineWeb difiere de otros conjuntos de datos para la IA en varios aspectos clave:
1. Calidad de los datos
A diferencia de muchos conjuntos de datos que contienen datos brutos sin filtrar, el conjunto de datos FineWeb se compone de datos que han sido cuidadosamente seleccionados y anotados para garantizar una alta calidad y la máxima relevancia. Este proceso de selección reduce el ruido y el sesgo de los datos, mejorando el rendimiento del modelo.
2. Estructura y diversidad
El conjunto de datos se compone de una amplia gama de datos web, que abarcan diferentes dominios y tipos de contenido. Esta diversidad permite a los modelos lingüísticos entrenarse en una gran variedad de información, lo que favorece una mejor generalización y una mayor adaptabilidad a tareas complejas. Además, el conjunto de datos FineWeb contiene millones de tokens, lo que contribuye a la diversidad y riqueza de los datos.
3. Actualización y mantenimiento permanente.
Hugging Face actualiza periódicamente el conjunto de datos FineWeb para incluir nuevos datos y corregir los errores existentes. Este mantenimiento continuo garantiza que los modelos de IA se mantengan actualizados con la información más reciente y las tendencias del lenguaje natural.
4. Compatibilidad con grandes modelos (LLM)
El conjunto de datos FineWeb se ha diseñado especialmente para satisfacer las necesidades de los modelos lingüísticos a gran escala, optimizando la estructura y el formato de los datos para facilitar su integración en los procesos de formación.
5. Enfoque ético y respeto de la intimidad.
En el contexto actual de creciente preocupación por la confidencialidad de los datos, el conjunto de datos FineWeb destaca por su respeto a las normas éticas en la recogida y utilización de datos web, garantizando un uso responsable en el marco de la adopción de herramientas y técnicas de inteligencia artificial.
💡 Ces caractéristiques font du FineWeb Dataset une ressource unique et précieuse pour l’entraînement des modèles d’intelligence artificielle, le positionnant comme une référence dans le domaine des datasets destinés à l’amélioration des modèles de langage.
-hand-innv.png)
¿Cómo contribuye FineWeb EDU a la formación y mejora de los modelos de inteligencia artificial?
Una variante de FineWeb, el FineWeb EDUcontribuye a la formación y mejora de modelos de inteligencia artificial ofreciendo un conjunto de datos específicamente diseñado para contextos educativos y de investigación. FineWeb EDU pretende transformar el mundo de la educación proporcionando datos de alta calidad para el aprendizaje y la investigación.
Esta versión del conjunto de datos pretende proporcionar a investigadores, estudiantes e instituciones académicas acceso a datos de alta calidad, al tiempo que está estructurada para facilitar el aprendizaje y la experimentación.
He aquí algunas de las formas en que FineWeb EDU desempeña un papel clave en la mejora de los modelos de IA:
1. Mayor accesibilidad
FineWeb EDU suele estar disponible para uso no comercial o académico, lo que permite a investigadores y estudiantes explorar y desarrollar sus propios modelos sin las restricciones financieras o legales que podrían asociarse a otros conjuntos de datos.
2. Datos preprocesados y anotaciones de calidad.
El conjunto de datos incluye anotaciones rigurosas y bien estructuradas, esenciales para el entrenamiento preciso de modelos de inteligencia artificial. Estas anotaciones permiten a los modelos aprender a partir de datos bien etiquetados, lo que reduce los errores y mejora la calidad de las predicciones.
3. Fomentar la innovación
Al poner los datos a disposición de la comunidad académica, FineWeb EDU fomenta el desarrollo de nuevos enfoques y técnicas de procesamiento del lenguaje natural y el aprendizaje automático. Los investigadores pueden experimentar libremente con estos datos, estimulando la innovación y los avances tecnológicos.
4. Actualización y adaptación.
Al igual que el conjunto de datos FineWeb estándar, FineWeb EDU se beneficia de actualizaciones periódicas para incluir los últimos datos web relevantes. Esto garantiza que los modelos de IA entrenados con estos datos se basan en la información más actualizada y son capaces de responder a los avances en el lenguaje natural.
5.Formación práctica
Al permitir a los usuarios experimentar directamente con datos reales, la FineWeb EDU ayuda a desarrollar habilidades prácticas en el uso de conjuntos de datos, la mejora de estos conjuntos de datos y, sobre todo, el modelado y la optimización del rendimiento de los modelos de IA.
¡💡 Gracias a estas características, FineWeb EDU desempeña un papel destacado en la educación y el desarrollo de habilidades de inteligencia artificial, al tiempo que contribuye a la mejora continua de los modelos lingüísticos y la investigación en el campo de la IA!
¿Está disponible el conjunto de datos FineWeb como código abierto y cómo repercute esto en la investigación sobre IA?
El conjunto de datos FineWeb está disponible en gran medida como código abierto, lo que significa que sus datos son de acceso público y pueden ser utilizados, modificados y compartidos por la comunidad. Este enfoque de código abierto ofrece los máximos beneficios a la comunidad de código abierto y a la investigación en inteligencia artificial:
1. Acceso abierto y colaboración.
El hecho de que el conjunto de datos FineWeb esté disponible como código abierto facilita la colaboración entre investigadores, desarrolladores e instituciones académicas. Pueden compartir sus experiencias, mejoras y descubrimientos, acelerando la innovación y la creación de nuevas técnicas en el campo del procesamiento del lenguaje natural y el aprendizaje automático.
2. Reducir las barreras de entrada
Al ser accesible para todos, el conjunto de datos FineWeb elimina los costes asociados a menudo a la adquisición de datos de alta calidad. Esto permite a investigadores independientes, startups y universidades trabajar en proyectos ambiciosos sin las limitaciones financieras, estimulando una diversidad de contribuciones y perspectivas en el campo de la IA. También es crucial compartir los logros y conectar con expertos en LinkedIn para mejorar la visibilidad y la colaboración.
3. Transparencia y reproducibilidad.
La disponibilidad de código abierto del conjunto de datos FineWeb fomenta la transparencia en el proceso de investigación. Gracias a las URL incluidas en el FineWeb Dataset, los investigadores pueden rastrear el origen de los contenidos y reproducir los experimentos realizados por otros equipos para validar los resultados. Esto mejora la credibilidad y fiabilidad de los estudios de entrenamiento para cada modelo de IA.
4. Mejora continua de los datos.
El código abierto permite a la comunidad contribuir a la mejora continua del conjunto de datos informando de errores, añadiendo nuevos datos u optimizando las anotaciones existentes. Esta colaboración activa garantiza que el conjunto de datos FineWeb evolucione y siga siendo relevante para las necesidades cambiantes de los modelos lingüísticos.
5. Innovación rápida
Al hacer accesibles sus datos, el conjunto de datos FineWeb estimula el rápido desarrollo de nuevas arquitecturas y técnicas de IA. Los investigadores pueden probar y perfeccionar sus modelos con una gran variedad de datos, lo que conduce a un progreso tecnológico más rápido y a aplicaciones más eficaces.
🪄 El impacto de hacer que un conjunto de datos como FineWeb esté disponible en código abierto es inmenso: democratiza el acceso a los recursos necesarios para desarrollar modelos cada vez más sofisticados, al tiempo que fomenta una cultura de intercambio y colaboración dentro de la comunidad científica.
Conclusión
El conjunto de datos FineWeb representa un gran avance en el campo de la inteligencia artificial: proporciona una base sólida para el entrenamiento de modelos lingüísticos, no sólo mejorando la precisión y el rendimiento de los algoritmos, sino también estimulando la investigación y la innovación dentro de la comunidad científica. Su versión educativa, FineWeb EDU, refuerza aún más su impacto al facilitar el acceso al aprendizaje y la experimentación a investigadores y estudiantes.
Estas características hacen del conjunto de datos FineWeb un recurso esencial para cualquiera que aspire a ampliar los límites de lo que pueden lograr los modelos de IA. Y si no es suficiente para usted, siempre puede ponerse en contacto con nosotros... nuestro equipo de etiquetadores de datos y especialistas en procesamiento de datos pueden ayudarle a enriquecer este conjunto de datos, por ejemplo. No dude en ponerse en contacto con nosotros.


