
Descubra los Small Language Models (SLM): hacia una Inteligencia Artificial más ligera y potente

Los rápidos avances en el campo de la inteligencia artificial han dado lugar a modelos lingüísticos cada vez más complejos, capaces de procesar cantidades masivas de datos y realizar diversas tareas con mayor precisión.
Sin embargo, estos grandes modelos lingüísticos, aunque eficaces, plantean problemas en términos de costes informáticos, consumo de energía y capacidad de despliegue en infraestructuras limitadas. En este contexto,los "pequeños modelos lingüísticos" (SLM) se perfilan como una alternativa prometedora.
Al reducir el tamaño de los modelos y mantener al mismo tiempo un rendimiento competitivo, estos modelos más ligeros ofrecen una solución para entornos con recursos limitados, al tiempo que satisfacen las crecientes demandas de flexibilidad y eficiencia. Además, las SLM ofrecen un mayor valor a largo plazo gracias a su mayor accesibilidad y versatilidad.
Un breve recordatorio: ¿cómo se desarrollan los modelos lingüísticos?
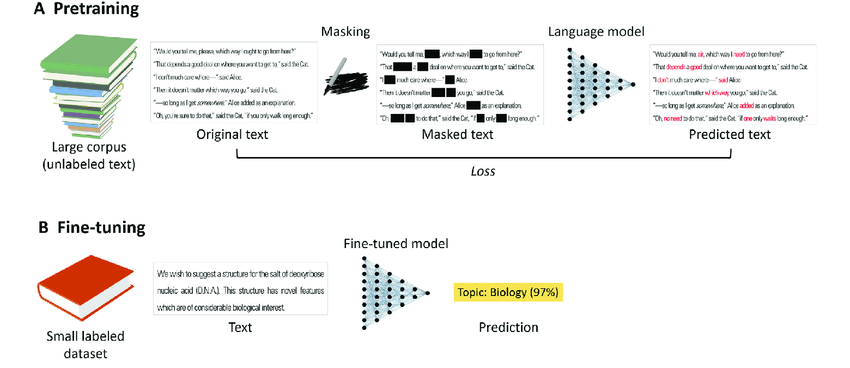
A) Modelos preentrenados
Los modelos lingüísticos se entrenan en tareas autosupervisadas utilizando grandes corpus de texto sin etiquetar. Por ejemplo, en la tarea de enmascaramiento lingüístico, se enmascara aleatoriamente una fracción de los tokens del texto original y el modelo lingüístico intenta predecir el texto original.
B) Modelos afinados
Los modelos lingüísticos (pre)entrenados suelen ajustarse a tareas específicas con texto etiquetado, utilizando un enfoque estándar de aprendizaje supervisado. El ajuste suele ser mucho más rápido y ofrece mejores resultados que el entrenamiento de un modelo desde cero, sobre todo cuando los datos etiquetados son escasos.
¿Qué es un Modelo de Lenguaje Reducido (SLM)?
Un Small Language Model (SLM) es un modelo de inteligencia artificial (IA) diseñado para procesar 🔗 lenguaje natural en inglés y otros idiomas, similar a los grandes modelos lingüísticos (LLM), pero con una arquitectura más pequeña y optimizada.
A diferencia de los LLM, que pueden requerir miles de millones de parámetros para funcionar, los SLM se diseñan con menos parámetros manteniendo un rendimiento aceptable para una gran variedad de tareas lingüísticas.
Esta reducción de tamaño significa que los SLM consumen menos recursos, son más rápidos de entrenar y desplegar y se adaptan mejor a entornos en los que la potencia de cálculo y la memoria son limitadas.
Aunque su capacidad de procesamiento es reducida en comparación con los modelos grandes, los SLM siguen funcionando bien para tareas específicas, especialmente cuando se optimizan con 🔗 datos anotados de alta calidad y técnicas de entrenamiento avanzadas. Además, las herramientas compactas y de alto rendimiento facilitan el acceso y el uso de estos modelos, lo que hace que su adopción sea más accesible para las empresas sin necesidad de conocimientos técnicos profundos.
-hand-innv.png)
¿Cuáles son las ventajas de las SLM frente a los modelos más grandes?
Los modelos lingüísticos pequeños (SLM) ofrecen una serie de ventajas sobre los modelos lingüísticos grandes (LLM), sobre todo en contextos en los que los recursos son limitados o la velocidad es esencial. Estas son las principales ventajas de los SLM:
Menos consumo de recursos
Los SLM requieren menos potencia de cálculo, memoria y espacio de almacenamiento, lo que facilita su implantación en dispositivos con recursos limitados, como smartphones o sistemas integrados.
Además, los modelos lingüísticos pequeños muestran una notable eficacia en el aprendizaje de escenarios 🔗 disparo ceroescenarios de aprendizaje, logrando resultados comparables o incluso mejores en algunas tareas de clasificación de textos.
Reducción de los costes de formación
Gracias a su menor tamaño, las SLM pueden accionarse más rápidamente y a menor coste, lo que reduce el gasto en energía e infraestructura informática.
Velocidad de procesamiento
Una arquitectura más ligera permite a los SLM realizar tareas con mayor rapidez, lo que resulta esencial para aplicaciones que requieren una respuesta en tiempo real (por ejemplo, un chatbot).
Despliegue flexible
Los SLM se adaptan mejor a diversos entornos, como plataformas móviles y sistemas empotrados, donde los modelos de gran tamaño no son viables debido a sus elevados requisitos de recursos.
Durabilidad
El uso de grandes modelos lingüísticos conlleva un elevado consumo de energía y una importante huella de carbono. Los SLM, con su menor necesidad de recursos, contribuyen a soluciones más ecológicas.
Optimización de tareas específicas
Aunque más pequeños, los SLM pueden ser extremadamente potentes para tareas específicas o dominios especializados, gracias a las técnicas de ajuste fino que permiten los conjuntos de datos de calidad reunidos mediante 🔗 procesos de anotación de datos de calidad.
Además, el rendimiento de los modelos lingüísticos pequeños para clasificar texto sin ejemplos demuestra que pueden rivalizar o incluso superar a los modelos grandes en determinadas tareas.
¿Qué papel desempeña la anotación de datos en la eficacia de los Small Language Models?
La anotación de datos desempeña un papel esencial en la eficacia de los Small Language Models (SLM). Dado que los SLM tienen una arquitectura más pequeña que los grandes modelos, dependen en gran medida de la calidad de los datos con los que se entrenan para compensar su tamaño limitado. Una anotación precisa y bien estructurada permite a los SLM aprender con mayor eficacia y mejorar su rendimiento en tareas específicas, como las de clasificación.
La anotación de datos también ayuda a orientar mejor el aprendizaje a dominios o aplicaciones concretos, lo que permite a los SLM especializarse y destacar en contextos específicos. Esto reduce la necesidad de procesar grandes cantidades de datos sin procesar y maximiza las capacidades de los modelos con datos anotados de alta calidad. En resumen, la anotación de datos optimiza el entrenamiento de los SLM, permitiendo construir conjuntos de datos de entrenamiento de muy alta calidad para lograr una mayor precisión y rendimiento a pesar de su reducido tamaño.
Retos y límites de los modelos lingüísticos reducidos
Los Small Language Models (SLM), aunque innovadores y prometedores, no están exentos de dificultades y limitaciones. Comprender estos aspectos es clave para evaluar su uso e impacto en diversos contextos. Le contaremos más en un próximo artículo.
Perspectivas de futuro para los modelos de lenguas pequeñas
Los Small Language Models (SLM) allanan el camino para muchas innovaciones y aplicaciones futuras. Su potencial de evolución e integración en diversos ámbitos es inmenso y ofrece perspectivas prometedoras para la inteligencia artificial.
Conclusión
Los Small Language Models (SLM) representan un gran paso adelante en la evolución de la inteligencia artificial, ya que ofrecen soluciones más ligeras, rápidas y accesibles, al tiempo que mantienen un rendimiento competitivo. Gracias a su flexibilidad y a sus reducidos requisitos de recursos, los SLM abren nuevas perspectivas para una gran variedad de aplicaciones, desde entornos con recursos limitados hasta industrias preocupadas por la sostenibilidad. A medida que evolucionen las tecnologías, estos modelos prometen desempeñar un papel central en el futuro de la IA.


