
Aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF): guía detallada

El Aprendizaje por Refuerzo a partir de la Retroalimentación Humana(RLHF) es una técnica de Aprendizaje Automático (ML) que utiliza la retroalimentación humana para garantizar que los grandes modelos lingüísticos (LLM) u otros sistemas de IA ofrezcan respuestas similares a las formuladas por los humanos.
El aprendizaje RLHF está desempeñando un papel revolucionario en la transformación de la inteligencia artificial. Se considera la técnica estándar de la industria para hacer que los LLM sean más eficientes y precisos en la forma en que imitan las respuestas humanas. El mejor ejemplo es ChatGPT. CuandoOpenAI estaban desarrollando ChatGPT, aplicaron RLHF al modelo GPT para que ChatGPT pudiera responder como lo hace hoy (es decir, de forma casi natural).
Esencialmente, RLHF incluye la aportación y la retroalimentación humanas en el modelo de aprendizaje por refuerzo. Esto ayuda a mejorar la eficacia de las aplicaciones de IA y las ajusta a las expectativas humanas.
Teniendo en cuenta la importancia y la utilidad del RLHF para desarrollar modelos complejos, la comunidad de investigación y desarrollo de la IA ha invertido mucho en este concepto. En este artículo, hemos intentado popularizar su principio, cubriendo todo lo que necesitas saber sobre el Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF), incluyendo su concepto básico, principio de funcionamiento, beneficios y mucho más. Si hay algo que hay que recordar, es que este proceso implica la movilización de moderadores / evaluadores en el ciclo de desarrollo de la IA. Innovatiana ofrece estos servicios de evaluación de la IA: no dude en ponerse en contacto con nosotros ¡!
Contenido: nuestra guía detallada de la RLHF
En IA, ¿qué es el Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF)?
El aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) es una técnica de aprendizaje automático (AM) que utiliza la retroalimentación humana para ayudar a los modelos de AM a autoaprender de forma más eficaz. Las técnicas de aprendizaje por refuerzo (RL)entrenan software/modelos para que tomen decisiones que maximicen las recompensas. Así se obtienen resultados más precisos.
RLHF consiste en incorporar la retroalimentación humana a la función de recompensa, haciendo que el modelo ML realice tareas que se correspondan con las necesidades y objetivos humanos. Proporciona al modelo la capacidad de interpretar correctamente las instrucciones humanas, aunque no estén descritas con claridad. Además, también ayuda al modelo existente a mejorar su capacidad de generar lenguaje natural.
Hoy en día, el RLHF se utiliza en todas las aplicaciones de la inteligencia artificial generativa, en particular en los modelos lingüísticos a gran escala (LLM).
El concepto fundamental del RLHF
Para comprender mejor el RLHF, es importante entender primeroaprendizaje por refuerzo (RL) y luego el papel de la retroalimentación humana en él.
El aprendizaje por refuerzo (RL) es una técnica de ML en la que el agente/modelo interactúa con su entorno para aprender a tomar decisiones. Para ello, realiza acciones que afectan a su entorno, lo mueven a un nuevo estado y le devuelven una recompensa. La recompensa que recibe es como una retroalimentación, que mejora la toma de decisiones del agente. Este proceso de retroalimentación continúa una y otra vez para mejorar la toma de decisiones del agente. Sin embargo, es difícil diseñar un sistema de recompensas eficaz. Aquí es donde entran en juego la interacción humana y la retroalimentación.
La retroalimentación humana resuelve las deficiencias del sistema de recompensa mediante una señal de recompensa humana a través de un supervisor humano. De este modo, la toma de decisiones del agente resulta más eficaz. La mayoría de los sistemas RLHF incluyen tanto la recogida de feedback humano como señales de recompensa automatizadas para un entrenamiento más rápido.
RLHF y su papel en los grandes modelos lingüísticos (LLM)
Para el público en general, incluidos los especialistas ajenos a la comunidad investigadora de la IA, cuando oímos hablar de RLHF, se relaciona principalmente con los grandes modelos lingüísticos (LLM). Como ya se ha mencionado, RLHF es la técnica estándar de la industria para hacer que los LLM sean más eficientes y precisos a la hora de imitar las respuestas humanas.
Los LLMS están diseñados para predecir la siguiente palabra/token de una frase. Por ejemplo, si ahora introduce el principio de una frase en un modelo de lenguaje GPT, éste la completará añadiendo palabras lógicas (o a veces alucinada o incluso sesgada - pero ese es otro debate).
Sin embargo, los humanos no sólo quieren que el LLM complete frases. Quieren que comprenda sus complejas peticiones y responda en consecuencia. Por ejemplo, supongamos que le pides al LLM que "escriba un artículo de 500 palabras sobre ciberseguridad". En este caso, puede que interprete las instrucciones incorrectamente y responda diciéndote cómo escribir un artículo sobre ciberseguridad en lugar de escribir un artículo para ti. Esto ocurre principalmente debido a un sistema de recompensa ineficaz. Esto es exactamente lo que implica RLHF para los LLM. ¿Me sigues?
RLHF mejora las capacidades de los LLM incorporando un sistema de recompensa con retroalimentación humana. De este modo, el modelo aprende a tener en cuenta los consejos de los humanos y a responder de la forma más acorde con sus expectativas. En resumen, RLHF es la clave para que los LLM respondan como los humanos. En cierto modo, también podría explicar por qué un modelo como ChatGPT presta más atención a las preguntas formuladas de forma cortés (como en la vida, un "por favor" en una pregunta tiene más probabilidades de obtener una respuesta de calidad).
-hand-innv.png)
¿Por qué es importante la RLHF?
El sector de la inteligencia artificial (IA) está en pleno auge con la aparición de una amplia gama de aplicaciones, como el procesamiento del lenguaje natural (PLN), los coches autónomos o las predicciones bursátiles, entre otras. Sin embargo, el objetivo principal de casi todas las aplicaciones de IA es imitar las respuestas humanas o tomar decisiones similares a las humanas.
Las RLHF desempeñan un papel fundamental en el entrenamiento de modelos/aplicaciones de IA para que respondan de forma más parecida a la humana. En el proceso de desarrollo de RLHF, el modelo da primero una respuesta que se parece en algo a la que podría formular un humano. Después, un supervisor humano (como nuestro equipo de moderadores en Innovatiana) da una respuesta directa y una puntuación a la respuesta basándose en varios aspectos que implican valores humanos, como el estado de ánimo, la amabilidad, los sentimientos asociados a un texto o imagen, etc. Por ejemplo, un modelo traduce un texto que parece técnicamente correcto, pero puede parecer poco natural al lector. Esto es lo que puede detectar la retroalimentación humana. De este modo, el modelo sigue aprendiendo de las respuestas humanas y mejora sus resultados para ajustarse a las expectativas humanas.
Si utilizas ChatGPT con regularidad, sin duda te habrás dado cuenta de que te ofrece opciones y a veces te pide que elijas la mejor respuesta. Sin saberlo, has participado en su proceso de formación, ¡como supervisor!
La importancia de la RLHF queda patente en los siguientes aspectos:
- Mayor precisión de la IA: mejora la precisión de los modelos incorporando un bucle adicional de retroalimentación humana.
- Facilitarparámetros de entrenamiento complejos: RLHF ayuda a la hora de entrenar modelos con parámetros complejos, como adivinar el sentimiento asociado a una pieza musical o a un texto (tristeza, alegría, estado de ánimo particular, etc.).
- Satisfacer a los usuarios: garantiza que los modelos respondan de forma más humana, lo que aumenta la satisfacción de los usuarios.
En resumen, RLHF es una herramienta del ciclo de desarrollo de la IA para optimizar el rendimiento de los modelos de ML y hacerlos capaces de imitar las respuestas y la toma de decisiones humanas.
Proceso de formación RLHF paso a paso
El aprendizaje por refuerzoa partir de la retroalimentación humana(RLHF) amplía el aprendizaje autosupervisado al que se someten los grandes modelos lingüísticos como parte del proceso de formación. Sin embargo, RLHF no es un modelo de aprendizaje autosuficiente, ya que el uso de evaluadores y formadores humanos encarece todo el proceso. En consecuencia, la mayoría de las empresas utilizan RLHF para afinar un modelo preentrenado, es decir, para completar un ciclo de desarrollo automatizado de IA con cierta intervención humana.
El proceso de desarrollo/formación de las RLHF paso a paso es el siguiente:
Paso 1. Preentrenamiento de un modelo lingüístico Preformación de un modelo lingüístico
El primer paso consiste en preentrenar el modelo lingüístico (como BERT, GPT o LLaMA, por citar sólo algunos) utilizando una gran cantidad de datos textuales. gran cantidad de datos textuales. Este proceso de entrenamiento permite al modelo lingüístico comprender los distintos matices del lenguaje humano, como la semántica o la sintaxis y, por supuesto, el lenguaje.

Las principales actividades de esta fase son las siguientes:
1. Elige un modelo de lenguaje básico para el proceso RLHF. Por ejemplo, OpenAI utiliza una versión ligera de GPT-3 para su modelo RLHF.
2. Recopilar datos brutos de Internet y otras fuentes y preprocesarlos para adecuarlos a la formación.
3. Entrenar el modelo lingüístico con los datos.
4. Evalúe el modelo lingüístico después del entrenamiento utilizando un conjunto de datos diferente.
Para que el LM adquiera más conocimientos sobre las preferencias humanas, los seres humanos participan en la generación de respuestas a los avisos o preguntas. Estas respuestas también se utilizan para entrenar el modelo de recompensa.
Paso 2. Entrenamiento de un modelo de recompensa Entrenamiento de un modelo de recompensa
Un modelo de recompensa es un modelo lingüístico que envía una señal de clasificación al modelo lingüístico original. Básicamente, sirve como herramienta de alineación que incorpora las preferencias humanas al proceso de aprendizaje de la IA. Por ejemplo, un modelo de IA genera dos respuestas a la misma pregunta, por lo que el modelo de recompensa indicará qué respuesta se acerca más a las preferencias humanas.

Las principales actividades implicadas en la formación del modelo de recompensa son las siguientes:
- Establecer el modelo de recompensa, que puede ser un sistema modular o un modelo lingüístico integral.
- Entrenarel modelo de recompensa con un conjunto de datos distinto del utilizado para preentrenar el modelo lingüístico. El conjunto de datos consta de pares de instrucciones y recompensas, es decir, cada instrucción refleja un resultado esperado con recompensas asociadas para presentar la conveniencia del resultado.
- Entrene el modelo utilizando pares de instrucciones y recompensas para asociar resultados específicos con los valores de recompensa correspondientes.
- Integrar la opinión humana en el entrenamiento del modelo de recompensa para perfeccionarlo. Por ejemplo, ChatGPT incorpora la opinión humana pidiendo a los usuarios que clasifiquen la respuesta haciendo clic con el pulgar hacia abajo o hacia arriba.
Tercer paso. Ajuste del modelo lingüístico o LM con aprendizaje por refuerzo
La etapa final y más crítica es el puesta a punto del modelo de comprensión del lenguaje natural con aprendizaje por refuerzo. Este ajuste es esencial para garantizar que el modelo lingüístico ofrezca respuestas fiables a las peticiones del usuario. Para ello, los especialistas en IA utilizan diversas técnicas de aprendizaje por refuerzo, comola Optimización de Política Próxima (PPO) y la Divergencia de Kullback-Leibler (KL).
Las principales actividades de refinado de LM son las siguientes:
1. La entrada del usuario se envía a la política RL (la versión ajustada de la LM). La política RL genera la respuesta. La respuesta de la política RL y la salida inicial de la LM son evaluadas por el modelo de recompensa, que proporciona un valor de recompensa escalar basado en la calidad de las respuestas.
2. El proceso anterior continúa en un bucle de retroalimentación, de modo que el modelo de recompensa sigue asignando recompensas a tantas muestras como sea posible. De este modo, la política de RL empezará gradualmente a generar respuestas al estilo humano.
3. La divergencia KL es un método estadístico para evaluar la diferencia entre dos distribuciones de probabilidad. Se utiliza para comparar la distribución de probabilidad entre las respuestas actuales de la política de RL con la distribución de referencia que refleja las mejores respuestas al estilo humano.
4. La Optimización de Políticas Proximales (PPO) es un algoritmo de aprendizaje por refuerzo que optimiza eficazmente las políticas en entornos complejos que implican espacios de estado/acción de alta dimensión. Es muy útil para refinar LM, ya que equilibra la explotación y la exploración durante el entrenamiento. Dado que los agentes de las RLHF deben aprender de la retroalimentación humana y de la exploración por ensayo y error, este equilibrio es vital. De este modo, la OOP ayuda a conseguir un aprendizaje robusto y más rápido.
Eso es todo, ¡y no está nada mal! Así es como funciona un proceso completo de entrenamiento de RLHF, empezando por un proceso de preentrenamiento y terminando con un agente de IA con un ajuste fino en profundidad.
¿Cómo se utiliza RLHF en ChatGPT?
Ahora que sabemos cómo funciona un RLHF, pongamos un ejemplo concreto: analicemos cómo se integra el RLHF en el proceso de entrenamiento de ChatGPT, el chatbot de IA más popular del mundo.
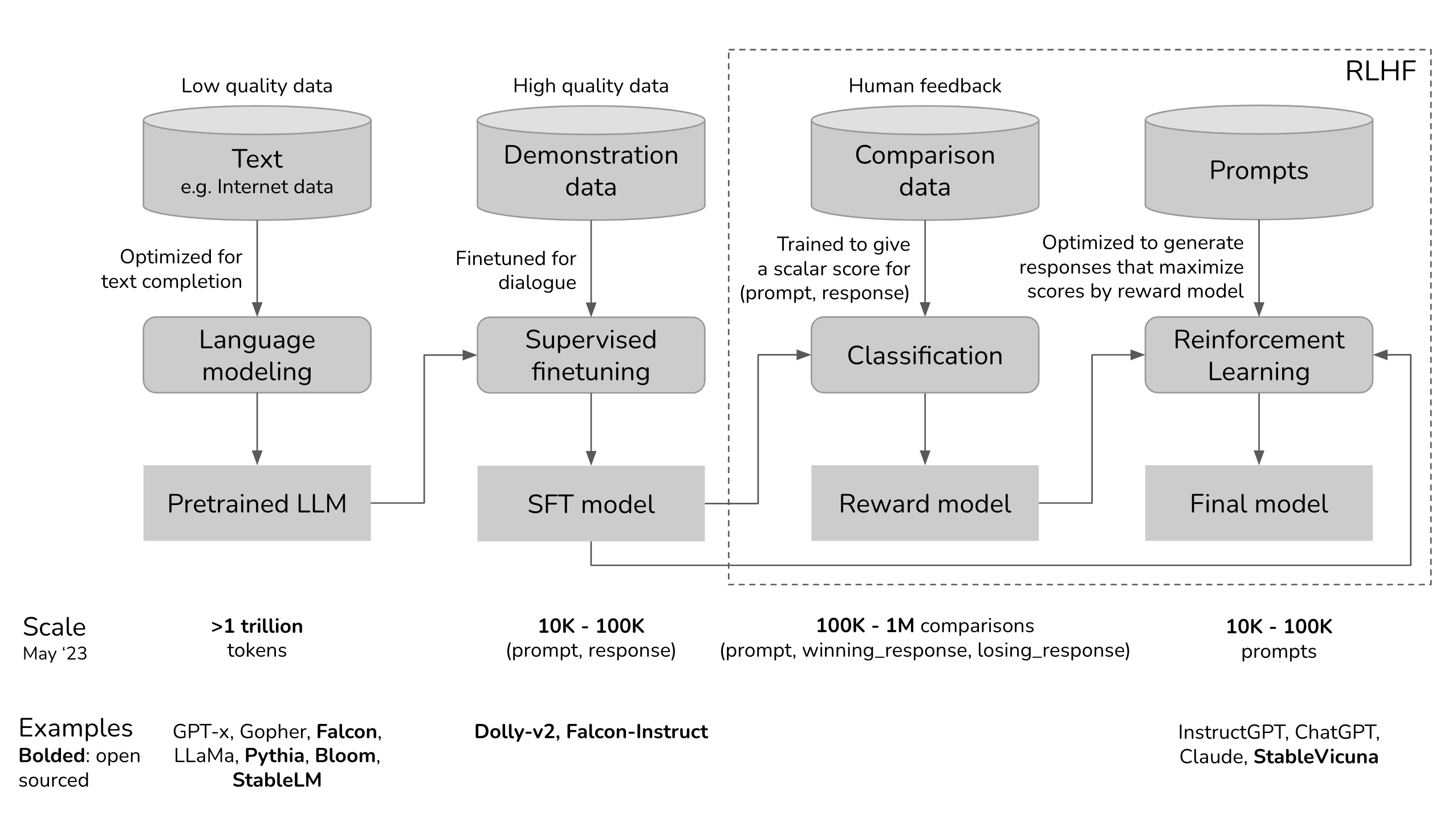
ChatGPT utiliza el marco RLHF para entrenar el modelo lingüístico y proporcionar respuestas adecuadas al contexto y similares a las humanas. Los tres pasos principales incluidos en su proceso de entrenamiento son:
1. Ajuste del modelo lingüístico
El proceso comienzautilizando datos de aprendizaje supervisado para perfeccionar el modelo lingüístico inicial. Para ello se crea un conjunto de datos de conversaciones en las que los formadores de IA desempeñan los papeles de asistente de IA y usuario. En otras palabras, los formadores de IA utilizan las sugerencias escritas por el modelo para escribir sus respuestas. De este modo, el conjunto de datos se construye con una mezcla de texto escrito por el modelo y texto generado por humanos, lo que supone una colección de varias respuestas del modelo.
2. Creación de un modelo de recompensa
Una vez refinado el modelo inicial, entra en juego el modelo de recompensa. En esta fase, el modelo de recompensa se crea para reflejar las expectativas humanas. Para ello, los anotadores humanos clasifican las respuestas generadas por el modelo en función de las preferencias humanas, la calidad y otros factores.
Las clasificaciones se utilizan para entrenar el segundo modelo de aprendizaje automático, denominado modelo de recompensa. Este modelo es capaz de predecir en qué medida la función de recompensa de una respuesta se ajusta a las preferencias humanas.
3. Mejora del modelo con aprendizaje por refuerzo
Una vez que el modelo de recompensa está listo, el último paso consiste en mejorar los resultados principales del modelo lingüístico y del modelo mediante el aprendizaje por refuerzo. Aquí, la Optimización de Políticas Proximales (PPO) ayuda al LLM a generar respuestas que puntúan más alto en el modelo de recompensa.
Los tres pasos anteriores son iterativos, es decir, se producen en un bucle para mejorar el rendimiento y la precisión del modelo en su conjunto.
¿Cuáles son los retos de utilizar RLHF en ChatGPT?
Aunque el RLHF en ChatGPT ha mejorado notablemente la eficacia de la respuesta, presenta algunos retos, como los siguientes:
- Cada ser humano tiene preferencias diferentes. Por eso es difícil definir un modelo de recompensa que satisfaga todos los tipos de preferencias.
- Depender de la mano de obra humana para optimizar las respuestas es costoso y lento (y a veces poco ético).
- Uso coherente de la lengua. Hay que prestar especial atención a la coherencia lingüística (inglés, francés, español, malgache, etc.) para mejorar las respuestas.
Ventajas del RLHF
De todo lo debatido hasta ahora se desprende que el RLHF desempeña un papel destacado en la optimización de las aplicaciones de IA. Algunas de las principales ventajas que ofrece son:
- Adaptabilidad: RLHF ofrece una estrategia de aprendizaje dinámica que se adapta en función de la retroalimentación. Esto le ayuda a adaptar su comportamiento en función de la retroalimentación/interacciones en tiempo real y a adaptarse bien a una amplia gama de tareas.
- Mejora continua: los modelos basados en RLHF son capaces de mejorar continuamente en función de las interacciones de los usuarios y de más comentarios. De este modo, seguirán mejorando su rendimiento con el paso del tiempo.
- Reducción del sesgo del modelo: RLHF reduce el sesgo del modelo al implicar la retroalimentación humana, lo que minimiza las preocupaciones sobre el sesgo del modelo o la sobregeneralización.
- Mayor seguridad : RLHF hace que las aplicaciones de IA sean seguras, porque el bucle de retroalimentación humana impide que los sistemas de IA desencadenen comportamientos inadecuados.
En resumen, el RLHF es la clave para optimizar los sistemas de IA y hacer que funcionen de forma acorde con los valores y las intenciones humanas.
Retos y limitaciones de la RLHF
La moda de las RLHF también conlleva una serie de retos y limitaciones. Algunos de los principales retos/limitaciones de RLHF son:
- Sesgo humano: es probable que el modelo RLHF pueda hacer frente al sesgo humano, ya que los evaluadores humanos pueden influir involuntariamente en sus sesgos de respuesta.
- Escalabilidad: dado que RLHF depende en gran medida de la información humana, es difícil ampliar el modelo para tareas de mayor envergadura debido a la gran demanda de tiempo y recursos.
- Dependencia del factor humano: La precisión del modelo RLHF está influida por el factor humano. Las respuestas humanas ineficaces, sobre todo en consultas avanzadas, pueden comprometer el rendimiento del modelo.
- Formulación de la pregunta: la calidad de la respuesta del modelo depende principalmente de la formulación de la pregunta. Si la formulación de la pregunta no es clara, es posible que el modelo siga sin ser capaz de responder adecuadamente a pesar de los amplios límites RLHF.
Conclusión - ¿Cuál es el futuro de la RLHF?
Sin duda, el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) promete un futuro brillante y está llamado a seguir desempeñando un papel importante en la industria de la IA. Con el objetivo principal de tener una IA que imite los comportamientos y mecanismos humanos, el RLHF seguirá mejorando este aspecto mediante técnicas nuevas/avanzadas. Además, cada vez se prestará más atención a resolver sus limitaciones y a garantizar un equilibrio entre las capacidades de la IA y las preocupaciones éticas. En Innovatiana, esperamos contribuir a los procesos de desarrollo en los que participe el RLHF: nuestros moderadores son especialistas, familiarizados con las herramientas y capaces de apoyarle en sus tareas más complejas de evaluación de la IA.


