
¿Cómo crear y anotar un conjunto de datos para la IA? Todo lo que necesita saber

Introducción: ¿qué es un conjunto de datos y por qué es importante para la inteligencia artificial?
Hoy vamos a analizar una etapa esencial, pero a menudo subestimada, del proceso de desarrollo: la creación y recopilación de conjuntos de datos para la Inteligencia Artificial (IA). Tanto si eres un profesional de los datos como un aficionado a la IA, esta guía pretende ofrecerte consejos prácticos sobre cómo crear un conjunto de datos sólido y fiable.
El 🔗 aprendizaje automático (Machine Learning, ML)una rama esencial de la Inteligencia Artificial, depende en gran medida de la calidad de los conjuntos de datos iniciales utilizados en los ciclos de desarrollo. Disponer de suficientes datos adecuados para aplicaciones específicas de Machine Learning es fundamental. Este artículo le dará una visión general de las mejores prácticas para crear conjuntos de datos para Machine Learning y utilizarlos para tareas específicas. Entenderá lo que se necesita para recopilar y generar los datos adecuados para cada algoritmo de Machine Learning.
💡 Recuerda, la IA se basa en 3 pilares: Conjuntos de datos, Potencia de cálculo y Modelos. Obtén más información 🔗 siguiendo este enlace Cómo evaluar un modelo de Machine Learning.
1. Comprender la importancia de un conjunto de datos de calidad para la IA
Cualquier proyecto de IA depende en gran medida de la 🔗 calidad de los datos sobre los que se entrena el modelo subyacente. Un conjunto de datos bien diseñado es para la IA lo que los buenos ingredientes son para un chef: esencial para un resultado excepcional. Un conjunto de datos para Machine Learning es, de hecho, un conjunto de datos utilizados para entrenar un modelo de ML. Crear un buen conjunto de datos es, por tanto, un paso crítico en el proceso de entrenamiento y evaluación de modelos de ML. Es importante entender cómo generar datos para Machine Learning y determinar qué datos se necesitan para crear un conjunto de datos completo y eficaz.
En la práctica, un conjunto de datos es :
- Una colección coherente de datos en diversos formatos (texto, números, imágenes, 🔗 vídeosetc.).
- Conjunto en el que cada valor está asociado a un atributo y a una observación, por ejemplo, datos sobre individuos con atributos como su edad, peso, dirección, etc.
- Un conjunto coherente de datos que se ha comprobado para garantizar la validez de las fuentes de datos, evitar trabajar con datos inexactos o sesgados, o que no cumplen las normas de propiedad intelectual.
Un conjunto de datos no es :
- Una simple recopilación aleatoria de datos: los conjuntos de datos deben estar estructurados y organizados de forma lógica y coherente.
- No hay control de calidad: la verificación y validación de los datos son esenciales para garantizar su fiabilidad.
- Siempre utilizables en su estado original: a menudo es necesario limpiar y transformar los datos antes de poder utilizarlos.
- Una fuente infalible: incluso los mejores conjuntos de datos pueden contener errores, problemas de calidad o sesgos que hay que analizar y corregir.
- Un conjunto estático: un buen conjunto de datos puede necesitar ser actualizado y revisado para seguir siendo relevante y útil.
La calidad y el tamaño de un conjunto de datos desempeñan un papel decisivo en la precisión y el rendimiento de un modelo de IA. En general, cuantos más datos fiables y de alta calidad tenga acceso un modelo, mejor será su rendimiento. Sin embargo, es importante encontrar un equilibrio entre la cantidad de datos almacenados para su procesamiento y los recursos humanos e informáticos necesarios para procesarlos.

2. Defina el objetivo de su conjunto de datos
Antes de embarcarse en la construcción de un conjunto de datos, es decir, antes de sumergirse en la laboriosa 🔗 recopilación de datosaclara el objetivo de tu IA. ¿Qué pretende conseguir? Esta definición guiará tus elecciones en cuanto a los tipos y el volumen de datos necesarios.
Obtención de datos: ¿debe utilizar un conjunto de datos existente, datos sintéticos o recopilarlos usted mismo?
Cuando se empieza a desarrollar IA sin datos, es útil recurrir a 🔗 conjuntos de datos públicos de código abierto. Estos conjuntos de datos, procedentes de comunidades de código abierto u organizaciones públicas, ofrecen una amplia gama de información útil para determinados casos de uso.
En ocasiones, los científicos de datos recurren a 🔗 datos sintéticos. ¿Qué son los datos sintéticos? Son datos generados artificialmente, a menudo mediante algoritmos, para simular datos reales. Se utilizan en diversos campos para entrenar y validar modelos cuando los datos reales son insuficientes, caros de obtener o para preservar la confidencialidad. Estos datos imitan las características estadísticas de los datos reales, lo que permite probar y perfeccionar los modelos de IA en un entorno controlado. Sin embargo, es preferible utilizar datos reales para evitar discrepancias entre las características de los datos sintéticos y los datos reales (estas discrepancias también se conocen como "distorsiones"). Aunque convenientes y relativamente sencillos de obtener, los datos sintéticos pueden hacer que los modelos de aprendizaje automático sean menos precisos o menos eficientes cuando se aplican a situaciones reales.
La importancia de la calidad de los datos...
Aunque los conjuntos de datos públicos o los datos sintéticos pueden aportar información valiosa, a menudo es más ventajoso recopilar tus propios datos, adaptados a tus necesidades específicas. Sea cual sea la fuente de tus datos, hay una constante: la calidad de los datos y la 🔗 necesidad de etiquetarlos correctamente para dotarlos de una capa de información semántica son aspectos importantes a tener en cuenta para tu trabajo en el campo de la IA.
-hand-innv.png)
3. Recogida de datos: una etapa estratégica en el proceso de desarrollo de la IA
La recopilación de datos de entrenamiento es una etapa crítica en el proceso de desarrollo de la IA. Cuanto más meticuloso y riguroso sea durante esta etapa, más eficaz será el algoritmo de ML. Recopilar tantos datos relevantes como sea posible, equilibrando su diversidad y representatividad con tus capacidades de hardware y software, es una tarea importante, aunque a menudo descuidada.
A la hora de construir y optimizar sus modelos de aprendizaje automático, su estrategia debería consistir enutilizar sus propios datos. Estos datos están naturalmente adaptados a sus necesidades específicas y representan la mejor manera de optimizar su modelo para los tipos de datos que encontrará en situaciones de la vida real. Dependiendo de la edad de tu empresa, deberías tener estos datos en tu propia empresa, en Data Lakes en el mejor de los casos, o en varias bases de datos estructuradas y no estructuradas recopiladas a lo largo de los años.
Aunque obtener datos internamente es uno de los mejores enfoques, a diferencia de las multinacionales, las organizaciones más pequeñas (sobre todo las empresas de nueva creación) no siempre tienen acceso a conjuntos de datos acumulados por miles de empleados. Así que hay que ser ingenioso e idear otras formas de obtener datos. He aquí dos métodos de probada eficacia:
Arrastrarse ydesguazar
- El rastreo consiste en escanear un gran número de páginas web que puedan ser de su interés.
- El"scraping" es el proceso de recogida de datos de estas páginas.
Estas tareas, que pueden variar en complejidad, recopilan distintos tipos de conjuntos de datos, como texto sin formato, texto introductorio para modelos específicos, texto con metadatos para modelos de clasificación, texto multilingüe para modelos de traducción e imágenes con pies de foto para entrenar 🔗 clasificación de imágenes o modelos de conversión de imagen a texto.
Utilización de conjuntos de datos distribuidos por los investigadores
Es probable que otros investigadores ya hayan abordado problemas similares al suyo. En este caso, puedes encontrar y utilizar los conjuntos de datos que han creado o utilizado. Si estos conjuntos de datos están disponibles gratuitamente en una plataforma de código abierto, puedes recuperarlos directamente. Si no, no dude en ponerse en contacto con los investigadores para ver si están dispuestos a compartir sus datos.
4. Limpieza y preparación de datos
Esta etapa consiste en comprobar el conjunto de datos para eliminar errores y duplicaciones, y estructurarlo. Un conjunto de datos limpio es esencial para un aprendizaje eficaz de la IA.
Formatear, limpiar y reducir datos
Hay tres pasos fundamentales para crear un conjunto de datos de calidad:
- Formateo de datos, que consiste en realizar comprobaciones para garantizar la coherencia de los datos. Por ejemplo, ¿es idéntico el formato de la fecha en cada entrada?
- Limpieza de datos, que consiste en eliminar los valores omitidos, erróneos o no representativos para mejorar la precisión del algoritmo.
- Reducción de datos, que consiste en reducir el tamaño del conjunto de datos eliminando la información irrelevante o menos relevante.
Estos pasos son esenciales para obtener un conjunto de datos útil y optimizado para el aprendizaje automático.
Preparación de los datos
Los conjuntos de datos suelen tener defectos que pueden afectar a la precisión y el rendimiento de los modelos de aprendizaje automático. Entre los problemas más comunes se encuentran el desequilibrio de clases (una clase predomina sobre otra), los datos que faltan (que comprometen la precisión y la generalización del modelo), el "ruido" (información incorrecta o irrelevante, como imágenes demasiado borrosas) y los valores atípicos (valores muy altos o muy bajos, que distorsionan los resultados). Para remediar estos problemas, los científicos de datos tienen que limpiar y preparar los datos previamente para garantizar la fiabilidad y eficacia del modelo.
Más datos
El 🔗 "aumento de datos" es una técnica clave en el aprendizaje automático para enriquecer un conjunto de datos. Consiste en crear nuevos datos a partir de los existentes mediante diversas transformaciones. Por ejemplo, en el tratamiento de imágenes, puede consistir en cambiar la iluminación, rotar o ampliar una imagen. Este método aumenta la diversidad de los datos, lo que permite a un modelo de IA aprender de una gama más amplia de ejemplos, mejorando así su capacidad de generalizar a nuevas situaciones.
Aumentar los conjuntos de datos es, sobre todo, una forma inteligente de incrementar la cantidad de datos de entrenamiento sin tener que recopilar nuevos datos reales.
5. Anotación: el lenguaje de sus datos
Anotar un conjunto de datos significa asignar etiquetas a los datos para hacerlos interpretables por la IA, una operación que requiere rigor y precisión porque influye directamente en la toma de decisiones del algoritmo, es decir, en la forma en que la IA procesará los datos. Esta tarea puede verse facilitada en gran medida por el uso de plataformas dedicadas a la anotación como 🔗 Kili, 🔗 V7 Labs o 🔗 Label Studio. Estas herramientas ofrecen interfaces intuitivas y funciones avanzadas para una anotación precisa, contribuyendo a la eficiencia y precisión de los modelos de Machine Learning.
La anotación de datos para la IA suele requerir la experiencia humana para etiquetar con precisión los datos, un paso esencial para el entrenamiento de los modelos. Cuanto más complejos sean sus conjuntos de datos, más específicos sean o más formación en reglas o mecanismos particulares se requiera, mayor será la necesidad de la pericia humana de los etiquetadores de datos. A medida que avanza la tecnología, las capacidades de anotación se complementan cada vez más con herramientas automatizadas. Estas herramientas utilizan algoritmos para 🔗 preanotar los datosreduciendo así el tiempo y el esfuerzo necesarios para la anotación manual, aunque siguen requiriendo la verificación y validación humanas para garantizar la exactitud y pertinencia de las etiquetas asignadas. Las últimas actualizaciones de las plataformas de etiquetado del mercado ofrecen funcionalidades avanzadas de selección o revisión automática, que hacen que el trabajo de anotación sea cada vez menos laborioso para los anotadores. 🔗 Gracias a estas herramientas, el etiquetado de datos se está convirtiendo en una profesión por derecho propio.
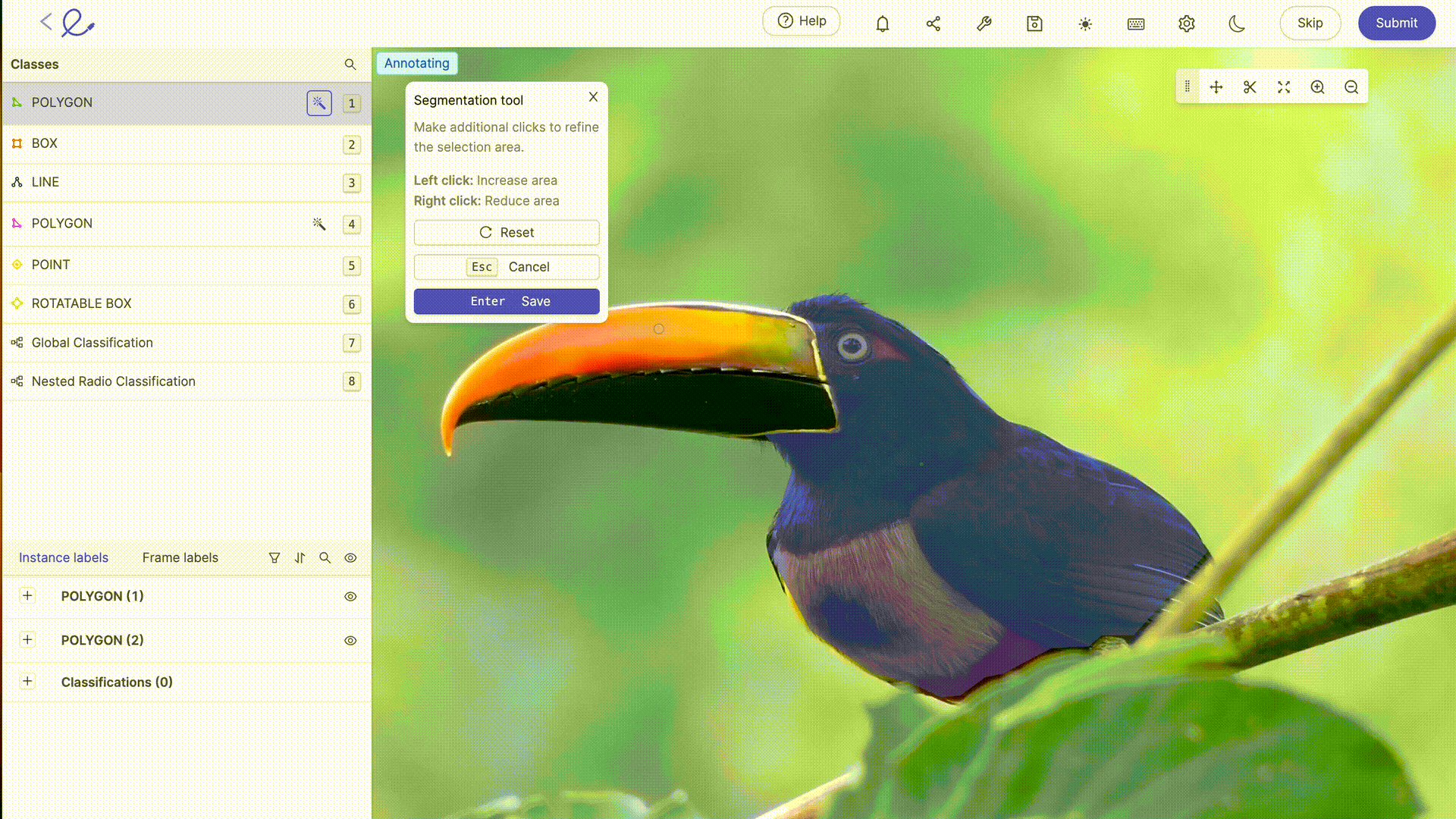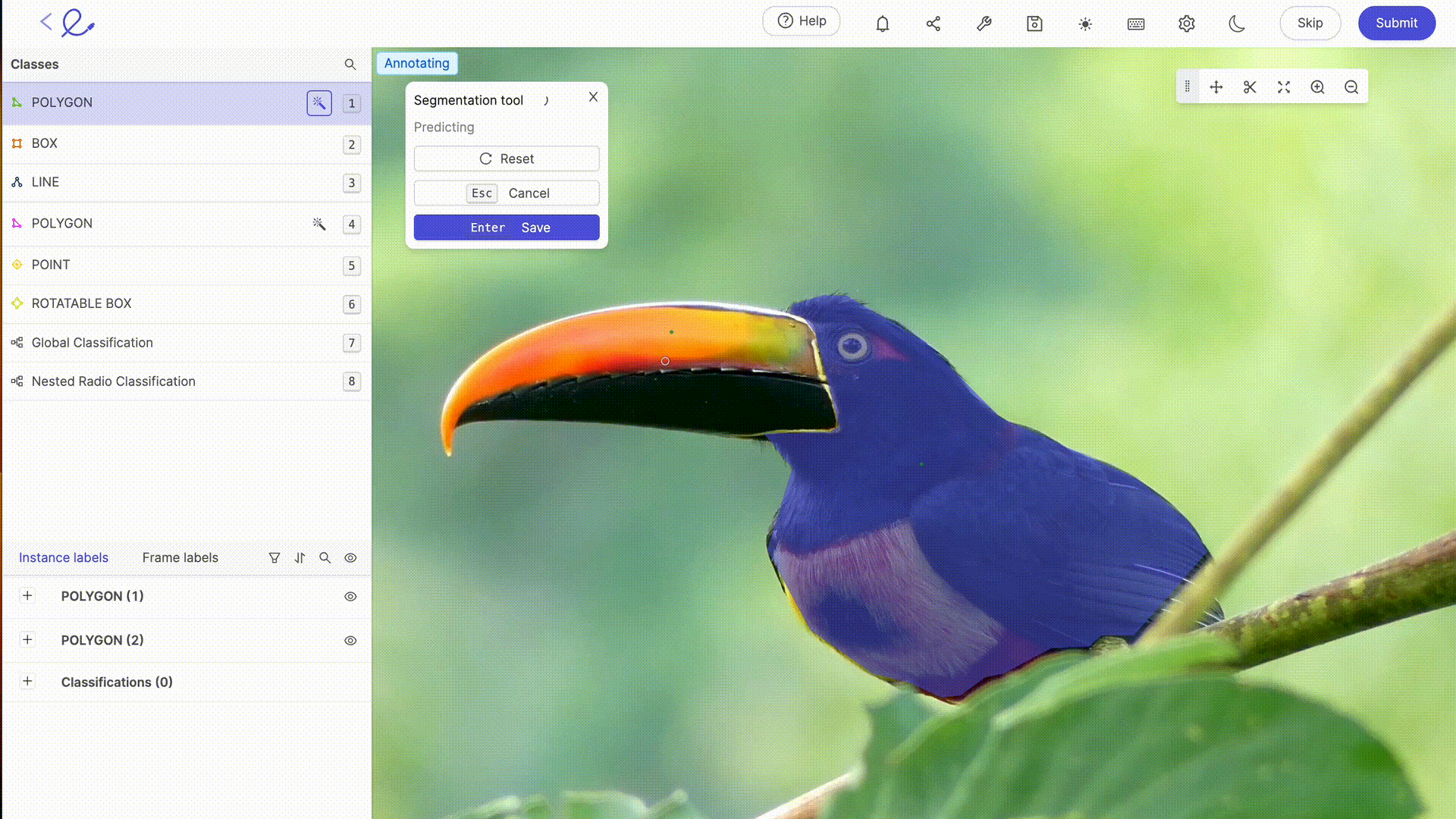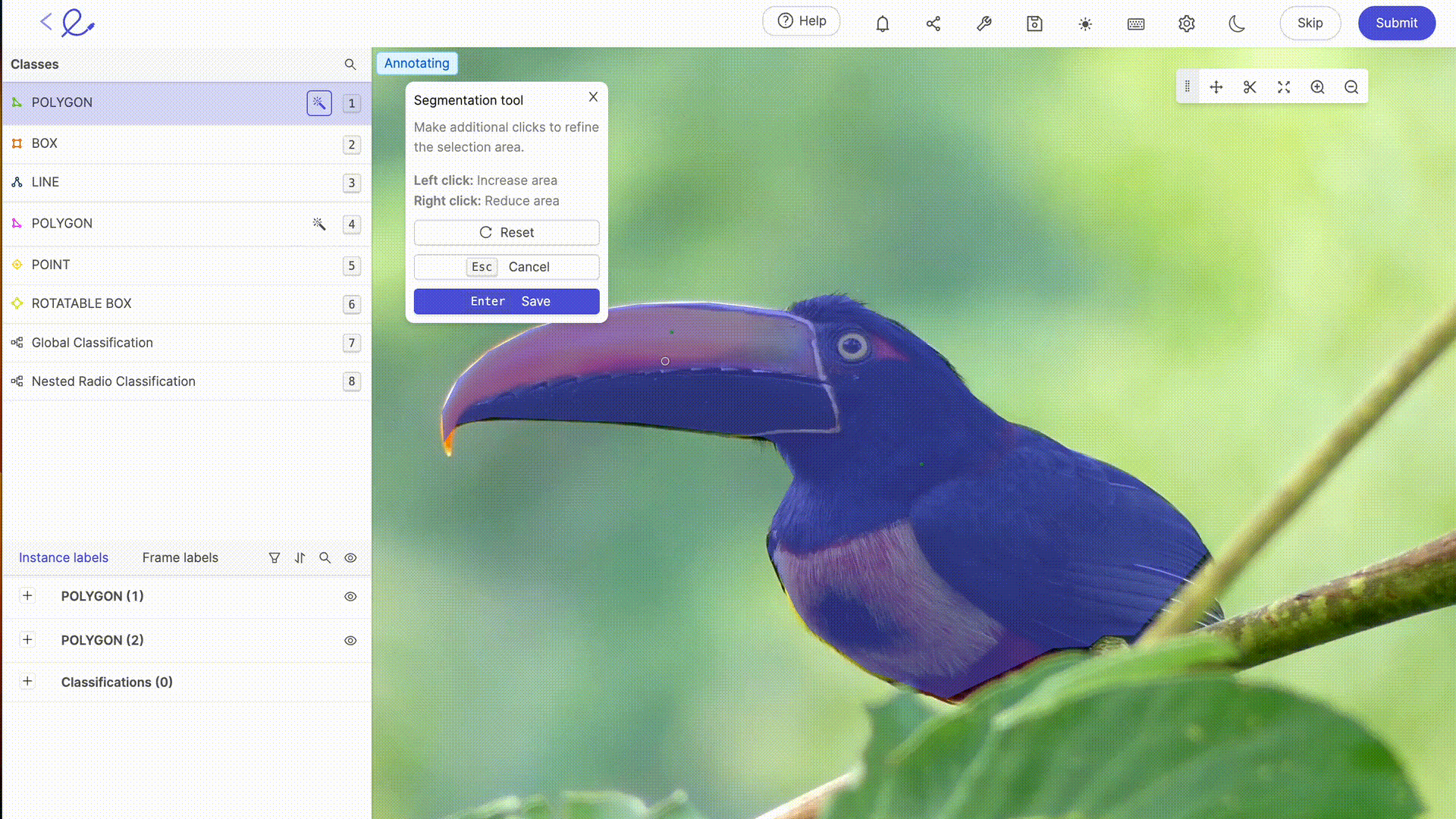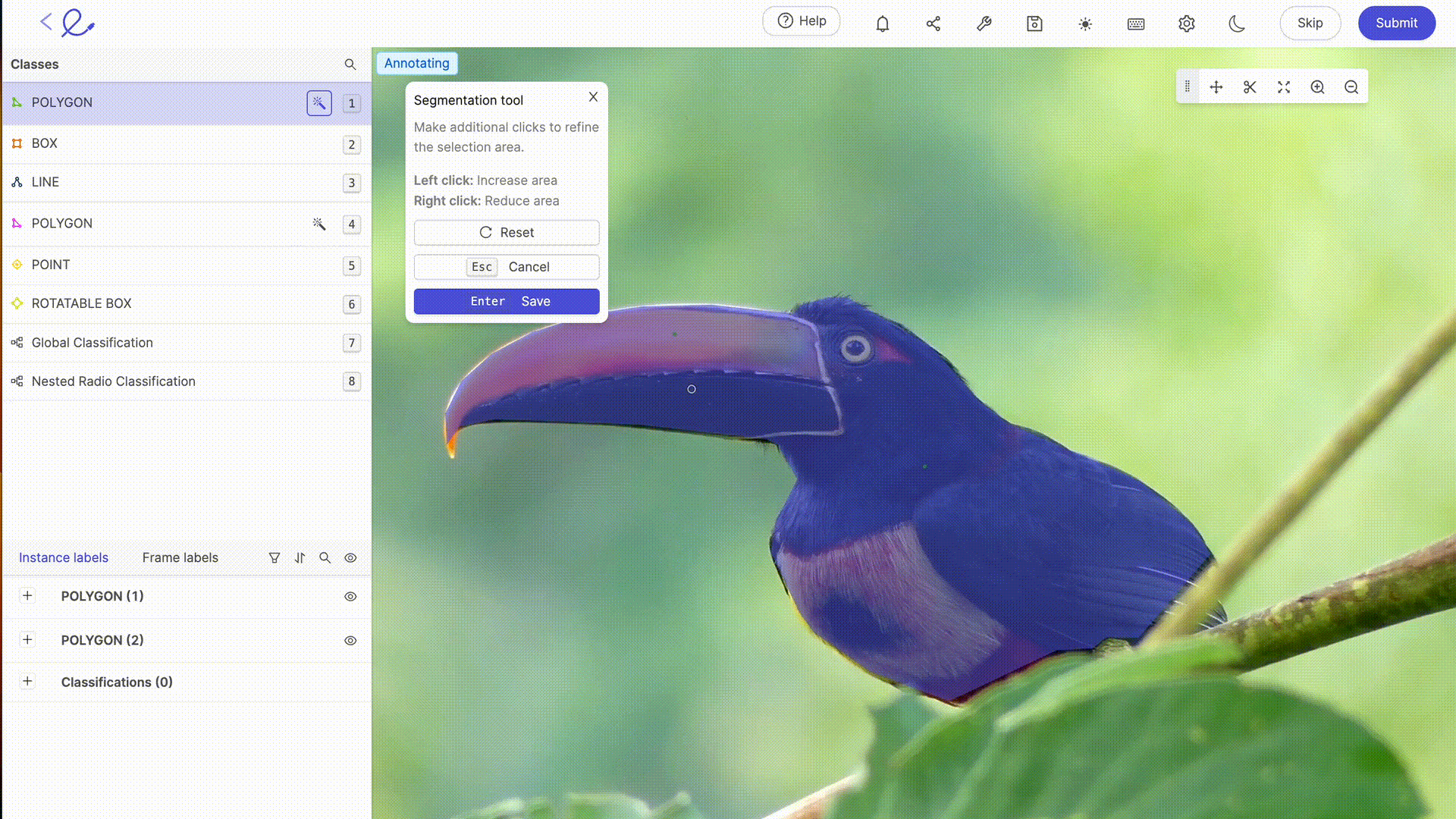
6. Optimización de un conjunto de datos: pruebas e iteración
Una vez que haya recopilado y anotado un volumen considerable de datos, el siguiente paso lógico es probar su conjunto de datos para evaluar el rendimiento de su modelo de IA. A partir de ahí, se trata deun enfoque iterativo, y tendrás que volver sobre las etapas anteriores para mejorar la calidad de los datos o las etiquetas producidas.
Para evaluar la calidad de un conjunto de datos, puede hacerse algunas preguntas:
- ¿Son los datos representativos de la población o del fenómeno estudiado?
- ¿Se han recogido los datos de forma ética y legal?
- ¿Son los datos lo suficientemente variados como para cubrir diferentes casos de uso?
- ¿Se ha visto afectada la calidad de los datos durante el ciclo de recogida y anotación, por ejemplo durante el proceso de transferencia o almacenamiento?
- ¿Contienen los datos sesgos o errores que puedan influir en los resultados del modelo?
- ¿Existen dependencias o correlaciones inesperadas entre las variables?
Estas preguntas le ayudarán a evaluar en profundidad la calidad de sus datos para garantizar la eficacia y fiabilidad de sus modelos de IA.
En conclusión...
Hemos llegado al final de este artículo. Como habrás podido comprobar, la creación y anotación de un conjunto de datos son pasos fundamentales en el desarrollo de soluciones de IA. Si sigues nuestros consejos, esperamos que puedas sentar las bases sólidas necesarias para entrenar modelos de IA fiables y de alto rendimiento. Buena suerte con tus experimentos y proyectos, y recuerda: ¡un buen conjunto de datos es la clave del éxito de tu proyecto de IA!
Por último, hemos elaborado una lista de los 10 mejores sitios para encontrar conjuntos de datos para el aprendizaje automático. Si esta lista le parece incompleta o tiene necesidades de datos más específicas, nuestro equipo está a su disposición para ayudarle a recopilar y anotar conjuntos de datos personalizados de alta calidad. 🔗 No dude en recurrir a nuestros servicios para perfeccionar sus proyectos de aprendizaje automático.
Nuestros 10 mejores sitios para encontrar conjuntos de datos para aprendizaje automático
- Conjunto de datos Kaggle: 🔗 https://www.kaggle.com/datasets
- Conjuntos de datos de caras abrazadas: 🔗 https://huggingface.co/docs/datasets/index
- Conjuntos de datos de Amazon: 🔗 https://registry.opendata.aws
- Buscador de conjuntos de datos de Google: 🔗 https://datasetsearch.research.google.com
- Plataforma de difusión de datos públicos del Gobierno francés: 🔗 https://data.gouv.fr
- Portal de datos abiertos de la Unión Europea: 🔗 http: //data.europa.eu/euodp
- Conjuntos de datos de la comunidad Reddit: 🔗 https://www.reddit.com/r/datasets
- Repositorio de aprendizaje automático de la UCI: 🔗 https://archive.ics.uci.edu
- Página web del INSEE: 🔗 https://www.insee.fr/fr/information/2410988
- Plataforma Nasa: 🔗 https://data.nasa.gov
(BONUS ) - SDSC, una plataforma para poner datos anotados a disposición de casos de uso médico: 🔗 https://www.surgicalvideo.io/


